
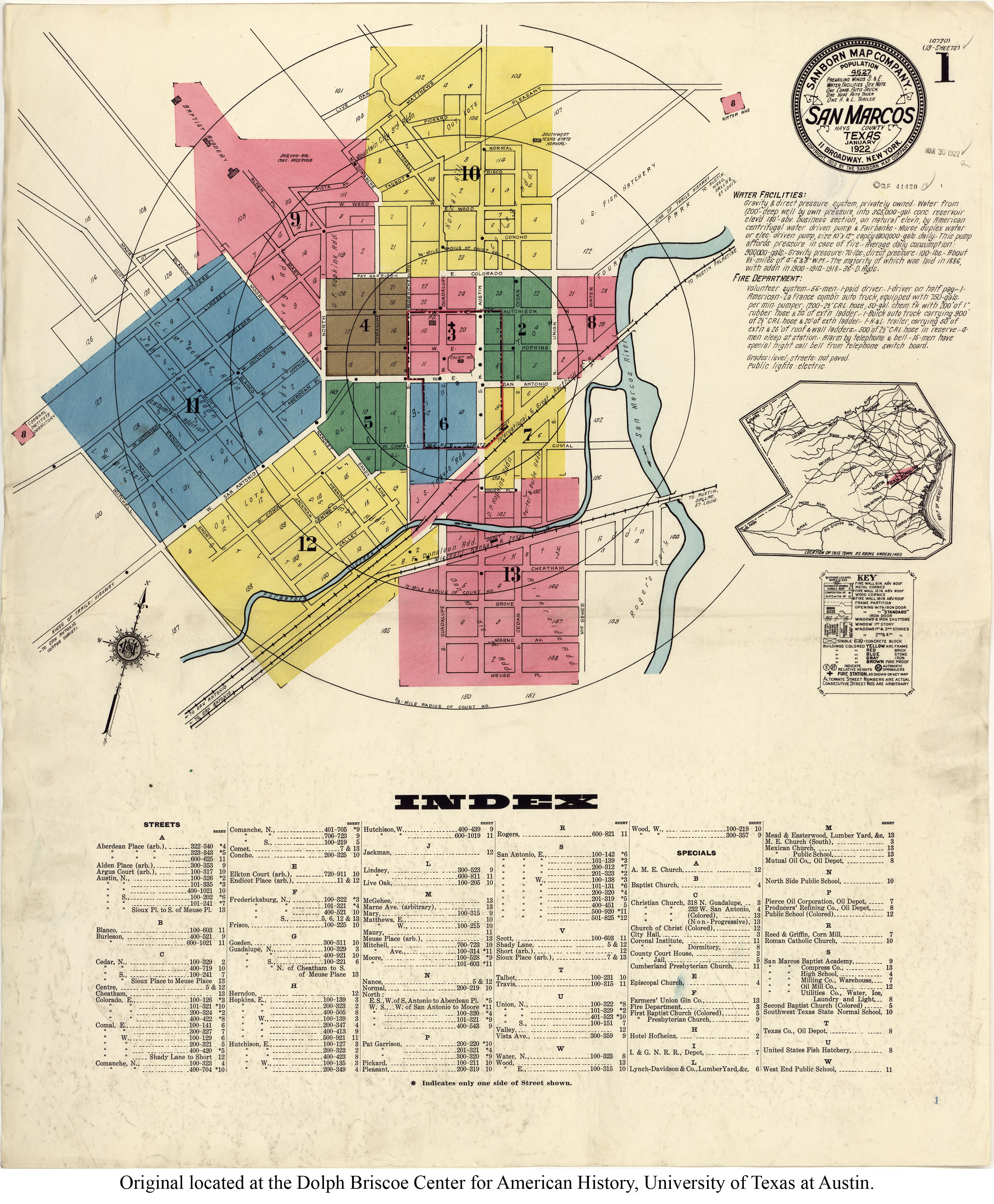
Digital & Web Services is continuing to capture images from our collection of negatives from the San Marcos Daily Record and uploading them to a Flickr site. One image from 1961 looked like a familiar intersection, Sessom and University in front of the Texas State University campus near the head of the San Marcos River and the old grist mill, now Kerbey Lane Cafe. The folder containing the negative labels it “Colorado St at Bridge.” Colorado Street was a previous name for what is now called University Drive which runs in front of Texas State past the round Theatre Center and River House (formerly the American Legion building) across the street.

However, zooming in on the street sign surprisingly reveals this is the corner of Jeff Davis and Olmos.

According to the San Marcos Daily Record (6-3-1971), the City Council voted to rename Olmos Dr. to Sessom Dr. in 1965, although even as of 1971 they still had not changed the street sign. Olmos is most likely derived from Olmos Creek in North San Antonio, which runs through Alamo Heights into the head waters of the San Antonio River. The San Marcos Public Library has a number of resources on the history of San Marcos. Olmos is not listed as a surname in any of the early San Marcos telephone directories, in the family name indexes for the Hays County Historical and Genealogical Society Quarterly, or in Dudley Dobie’s A brief history of Hays County and San Marcos, Texas.
The street running in front of the University has changed names a few times over the years and has included the name King of Trails Highway, according to a 1922 Sanborn Insurance map. Although officially named Colorado Street, in 1931 it also became Jeff Davis Hwy. In 2016, Texas State University removed a marker along University Dr. installed in 1931 designating the route as the “Jefferson Davis Memorial Highway No. 2.” There is a similar marker along South Congress Avenue in Austin.
A University task force recently released a report titled Historical Background and Context: Sallie Ward Beretta and John Garland Flowers. The task force conducted a scholarly analysis of two important persons in the history of Texas State that have buildings named after them. A section of the report relevant to the question of the street names, is a section that describes Sallie Ward Beretta’s role with the United Daughters of the Confederacy (UDC) project to rename existing roads in Texas in honor of the president of the Confederate States of America. ( A previous blog post discussed the digital restoration of a painting of Sallie Ward Beretta).













{kind=link}