
I recently read Michael J. Bennett‘s article, Countering Stryker’s Punch: Algorithmically Filling the Black Hole, in the latest edition of code4lib and wow, great stuff!
Bennett is comparing Adobe Photoshop’s Content Aware Fill tool and a GIMP technique I haven’t seen before as part of a workflow to digitally restore areas in photographs with no picture due to a hole punch having been taken to the physical negative. Part of Roy Stryker’s legacy at the FSA. You can read more about the negatives in Bennett’s article, this recent feature by Alan Taylor in The Atlantic and in Eric Banks’s review of what sounds like an amazing gallery show by William E. Jones in NY in 2010 in The Paris Review.

Library of Congress Search Results
I have been dipping my toes into computer vision recently and thought expanding upon Bennett’s work seems a good and educating challenge. A quick search at the Library of Congress returns nearly 2,500 results so this would also be a pretty good-sized data set to work on for a beginner with a bunch of exceptions and tweaking for edge-cases, but also a LOT of images and metadata to gather!
Luckily Coincidentally, the Library of Congress, who have digital scans of the punched negatives, recently advertised a new JSON API to access their materials so one could learn how to hook Python into their JSON API and automate data gathering.
I highly suggest starting with the Library of Congress’s Github account and their data-exploration repository, specifically the LOC.gov JSON API.ipynb Jupyter Notebook. If you’re new to working with code they make getting started much simpler. A Jupyter Notebook runs in your browser and consists of a column of cells. Each cell is a text box that can contain Markdown or code. Any code you write you can run right in the page and it will print any output to the page. You can display multi-media, too. I think of it like a blog post with in-line code and use it as a sandbox for building ideas.
I need to get a handle on version control and backing my code up to Github so it’s easily accessible, but the following is a very edited account of my recent travels in cyberspace.
Getting JSON back from a query
# import libraries from __future__ import print_functionimport requests# set our search url and payload as shown in the quick start guide for requests# http://docs.python-requests.org/en/master/user/quickstart/url = 'https://loc.gov/pictures/search/'# payload info is pulled from: https://www.loc.gov/pictures/apipayload = {'q': 'Negative has a hole punch made by FSA staff to indicate that the negative should not be printed.', 'fo': 'json'}response_json = requests.get(url, params=payload).json()print(response_json) # print response
Output
{u'search': {u'hits': 2458, u'focus_item': None, u'sort_by': None, u'field': None, u'sort_order': None, u'do_facets': True, u'query': u'Negative has a hole punch made by FSA staff to indicate that the negative should not be printed.', u'type': u'search'}, u'links': {u'json': u'//loc.gov/pictures/search/?q=Negative+has+a+hole+punch+made+by+FSA+staff+to+indicate+that+the+negative+should+not+be+printed.&fo=json', u'html': u'//loc.gov/pictures/search/?q=Negative+has+a+hole+punch+made+by+FSA+staff+to+indicate+that+the+negative+should+not+be+printed.', u'rss': u'//loc.gov/pictures/search/?q=Negative+has+a+hole+punch+made+by+FSA+staff+to+indicate+that+the+negative+should+not+be+printed.&fo=rss'}, u'views': {u'current': u'list', u'list': u'//www.loc.gov/pictures/search/?q=Negative+has+a+hole+punch+made+by+FSA+staff+to+indicate+that+the+negative+should+not+be+printed.', u'grid': u'//www.loc.gov/pictures/search/?q=Negative+has+a+hole+punch+made+by+FSA+staff+to+indicate+that+the+negative+should+not+be+printed.&st=grid', u'gallery': u'//www.loc.gov/pictures/search/?q=Negative+has+a+hole+punch+made+by+FSA+staff+to+indicate+that+the+negative+should+not+be+printed.&st=gallery', u'slideshow': u'//www.loc.gov/pictures/search/?q=Negative+has+a+hole+punch+made+by+FSA+staff+to+indicate+that+the+negative+should+not+be+printed.&st=slideshow'}, u'facets': [{u'type': u'displayed', u'filters': [{u'count': 2458, u'on': u'//www.loc.gov/pictures/search/?q=Negative+has+a+hole+punch+made+by+FSA+staff+to+indicate+that+the+negative+should+not+be+printed.&fa=displayed%3Aanywhere&sp=1&fo=json', u'selected': False, u'off': u'//www.loc.gov/pictures/search/?q=Negative+has+a+hole+punch+made+by+FSA+staff+to+indicate+that+the+negative+should+not+be+printed.&sp=1&fo=json', u'title': u'Larger image available anywhere'}, {u'count': 0, u'on': u'//www.loc.gov/pictures/search/?q=Negative+has+a+hole+punch+made+by+FSA+staff+to+indicate+that+the+negative+should+not+be+printed.&fa=displayed%3Alc_only&sp=1&fo=json', u'selected': False, u'off': u'//www.loc.gov/pictures/search/?q=Negative+has+a+hole+punch+made+by+FSA+staff+to+indicate+that+the+negative+should+not+be+printed.&sp=1&fo=json', u'title': u'Larger image available only at the Library of Congress'}, {u'count': 0, u'on': u'//www.loc.gov/pictures/search/?q=Negative+has+a+hole+punch+made+by+FSA+staff+to+indicate+that+the+negative+should+not+be+printed.&fa=displayed%3Anot_digitized&sp=1&fo=json', u'selected': False, u'off': u'//www.loc.gov/pictures/search/?q=Negative+has+a+hole+punch+made+by+FSA+staff+to+indicate+that+the+negative+should+not+be+printed.&sp=1&fo=json', u'title': u'Not Digitized'}], u'title': u'displayed'}], u'suggestions': {u'possible': []}, u'focus': None, u'collection': None, u'results': [{u'source_created': u'1997-05-08 00:00:00', u'index': 1, u'medium': u'1 negative : nitrate ; 35 mm.', u'reproduction_number': u'LC-USF33-002983-M3 (b&w film nitrate neg.)\nLC-DIG-fsa-8a10673 (digital file from original neg.)', u'links': {u'item': u'//www.loc.gov/pictures/item/2017724471/', u'resource': u'//www.loc.gov/pictures/item/2017724471/resource/'}, u'title': u'[Untitled photo, possibly related to: U.M.W.A. (United Mine Workers of Ameri
That was only 10% of the whole output!
Well, it was actually the number of characters received divided by 10 without the remainder.* The JSON is pretty readable, but still a lot to digest.
Two things in the output I notice right away are the word hits and the number 2458. This is probably the total hits returned on our query. The total number of results, or hits, is a metric I probably want to know for just about every search so some baby functions to save time typing later.
# import libraries
from __future__ import print_function # I'm using Python 2.7
import requests
# define functions
# get the json
def get_loc_json(url, payload):
return requests.get(url, params = payload).json()
# search function with optional collection
def query_loc_json(query, collection=None):
# we'll try everything in https
url = 'https://www.loc.gov/pictures/search/'
# we need a payload of parameters for our search function
# that are in key: value pairs
# Code for payload comes from the loc.gov API page
if collection is not None:
payload = { \
'q': query,
'co': collection,
'fo': 'json'
}
elif collection is None:
payload = { \
'q': query,
'fo': 'json'}
# give us back json!
return get_loc_json(url, payload)
# how many hits for a query do we receive
def get_loc_hits(response_json):
return response_json['search']['hits']
query = 'Negative has a hole punch made by FSA staff to indicate that the negative should not be printed.'
response_json = query_loc_json(query)
loc_hits = get_loc_hits(response_json)
print("Your search '{}' returned {} hits.".format(query, loc_hits))
Output
Your search 'Negative has a hole punch made by FSA staff to indicate that the negative should not be printed.' returned 2458 hits.
How about titles?
Yep, we can get those too, but instead of being under search like hits is, the information we want now is the actual title for items returned by our query. Looking at the API documentation we can see that items are returned in results and each result has a title. I am appending a new line to the end of each title by adding '\n' to item['title'] just so the output is a bit easier to read.
for item in response_json['results']:
print(item['title'] + '\n')Output
[Untitled photo, possibly related to: U.M.W.A. (United Mine Workers of America) official, Herrin, Illinois. General caption: Williamson County, Illinois once produced 11,000,000 tons of coal a year, and led the state in output. Since 1923 output has steadily declined until now it falls short of 2,000,000 tons. At one time, sixteen mine whistles blowing to work could be heard from the center of Herrin. Now only two mines are working and these two will probably be abandoned within the next year. The Herrin office of the U.M.W.A. was once the most active in the state. Today it is no longer self sustaining. These pictures were taken in the Herrin U.M.W.A office on a day when the mines were not working] [Untitled photo, possibly related to: Sunday school picnic. Much of the food brought into abandoned mining town of Jere, West Virginia by "neighboring folk" from other parishes. There is a great deal of "hard feelings" and many fights between Catholics and Protestants. Miners as a whole are not very religious, many not having any connections with church, though they may have religious background. Hard times has caused this to a certian extent. As one said, "The Catholic church expected us to give when we just didn't have it"] [Untitled photo, possibly related to: Loafers' wall, at courthouse, Batesville, Arkansas. Here from sun up until well into the night these fellows, young and old, "set". Once a few years ago a political situation was created when an attempt was made to remove the wall. It stays. When asked what they do there all day, one old fellow replied: "W-all we all just a 'set'; sometimes a few of 'em get up and move about to 'tother side when the sun gets too strong, the rest just 'sets'."] [Untitled photo, possibly related to: Loafers' wall, at courthouse, Batesville, Arkansas. Here from sun up until well into the night these fellows, young and old, "set". Once a few years ago a political situation was created when an attempt was made to remove the wall. It stays. When asked what they do there all day, one old fellow replied: "W-all we all just a 'set'; sometimes a few of 'em get up and move about to 'tother side when the sun gets too strong, the rest just 'sets'."] [Untitled photo, possibly related to: Loafers' wall, at courthouse, Batesville, Arkansas. Here from sun up until well into the night these fellows, young and old, "set". Once a few years ago a political situation was created when an attempt was made to remove the wall. It stays. When asked what they do there all day, one old fellow replied: "W-all we all just a 'set'; sometimes a few of 'em get up and move about to 'tother side when the sun gets too strong, the rest just 'sets'."] [Untitled photo, possibly related to: Wife of a prospective client, Brown County, Indiana. Husband and wife will be resettled on new land when their property has been purchased by the government] [Untitled photo, possibly related to: Wife of a prospective client, Brown County, Indiana. Husband and wife will be resettled on new land when their property has been purchased by the government] [Untitled photo, possibly related to: Wife of a prospective client, Brown County, Indiana. Husband and wife will be resettled on new land when their property has been purchased by the government] [Untitled photo, possibly related to: Wife of a prospective client, Brown County, Indiana. Husband and wife will be resettled on new land when their property has been purchased by the government] [Untitled photo, possibly related to: Jefferson furnace-made iron for "Monitor" in Civil War, not far from Jackson, Ohio] [Untitled photo, possibly related to: Home of a family of ten that has been on relief for eighteen months, Brown County, Indiana] [Untitled photo, possibly related to: Home of a family of ten that has been on relief for eighteen months, Brown County, Indiana] [Untitled photo, possibly related to: Home of a family of ten that has been on relief for eighteen months, Brown County, Indiana] [Untitled photo, possibly related to: Home of a family of ten that has been on relief for eighteen months, Brown County, Indiana] [Untitled photo, possibly related to: Home of a family of ten that has been on relief for eighteen months, Brown County, Indiana] [Untitled photo, possibly related to: Home of a family of ten that has been on relief for eighteen months, Brown County, Indiana] [Untitled photo, possibly related to: Home of a family of ten that has been on relief for eighteen months, Brown County, Indiana] [Untitled photo, possibly related to: Home of a family of ten that has been on relief for eighteen months, Brown County, Indiana] [Untitled photo, possibly related to: The "water company" was formed by the people in abandoned mining town of Jere, West Virginia, after the coal company cut off all public services because they were abandoning the mine. The coal company used to charge one dollar and twenty-cove cents per month for water. The present "people's" water company charges its members twenty-five cents per month and makes money at that even when everyone can't pay dues. There are dividends of flour, sugar, lard, etc. The lock is necessary to keep people from other camps from stealing the water, which is very scarce. It's still necessary to change the lock about every four months] [Untitled photo, possibly related to: One of the more elaborate gopher holes, equipped with a screen shaker, Williamson County, Illinois]
Long titles!
Yes, and how many titles did we receive? We could count, but we can quickly find the number of items in results with len()
len(response_json['results'])Output
20How long are the individual titles?
Good thinking! If we can find the number of items in results 20 and we have already located the title for each respective result can we figure out how long each of those titles are?
Can we also identify the shortest and longest titles out of our 20 while we’re at it?
Could we Tweet full titles?
# we will use enumerate to get an index number for each result
# https://docs.python.org/2/library/functions.html#enumerate
for index, result in enumerate(response_json['results'], start=1): # default start=0
title = result['title'] # title for each result
title_length = len(title) # length of title for each result
# is it the longest?
if longest_title == None: # If None titles then
longest_title = title # title must be longest
elif title_length > len(longest_title): # else if our title is longer than the longest title
longest_title = title # our title is the new longest_title
# is it the shortest?
if shortest_title == None:
shortest_title = title
if title_length < len(shortest_title):
shortest_title = title
# is it Tweetable?
if title_length <= 140: # is it less than or equal to 140?
is_tweetable = True # then yes it is!
else:
is_tweetable = False # Otherwise, nope
print('Title {}: {} characters.'format(index, title_length))
print('Is tweetable: {}'.format(is_tweetable)
print('\n' + 'Longest title contains {} characters.'.format(len(longest_title))) # add new line to it's easier to read
print(longest_title)
print('\n' + 'Shortest title contains {} characters'.format(len(shortest_title)))
print(shortest_title)Output
Title 1: 708 characters. Is tweetable: False Title 2: 531 characters. Is tweetable: False Title 3: 485 characters. Is tweetable: False Title 4: 485 characters. Is tweetable: False Title 5: 485 characters. Is tweetable: False Title 6: 195 characters. Is tweetable: False Title 7: 195 characters. Is tweetable: False Title 8: 195 characters. Is tweetable: False Title 9: 195 characters. Is tweetable: False Title 10: 121 characters. Is tweetable: True Title 11: 129 characters. Is tweetable: True Title 12: 129 characters. Is tweetable: True Title 13: 129 characters. Is tweetable: True Title 14: 129 characters. Is tweetable: True Title 15: 129 characters. Is tweetable: True Title 16: 129 characters. Is tweetable: True Title 17: 129 characters. Is tweetable: True Title 18: 129 characters. Is tweetable: True Title 19: 665 characters. Is tweetable: False Title 20: 137 characters. Is tweetable: True Longest title contains 708 characters. [Untitled photo, possibly related to: U.M.W.A. (United Mine Workers of America) official, Herrin, Illinois. General caption: Williamson County, Illinois once produced 11,000,000 tons of coal a year, and led the state in output. Since 1923 output has steadily declined until now it falls short of 2,000,000 tons. At one time, sixteen mine whistles blowing to work could be heard from the center of Herrin. Now only two mines are working and these two will probably be abandoned within the next year. The Herrin office of the U.M.W.A. was once the most active in the state. Today it is no longer self sustaining. These pictures were taken in the Herrin U.M.W.A office on a day when the mines were not working] Shortest title contains 121 characters. [Untitled photo, possibly related to: Jefferson furnace-made iron for "Monitor" in Civil War, not far from Jackson, Ohio]
Where are the other 2,438 items?
This is where the Library of Congress’s JSON API examples were very helpful: moving from page to page. Though, my code ended up a bit different from theirs.
response_json = query_loc_json(query)
while True: # only get a next page if there is one!
for result in response_json['results']:
print(result['index']) # we didn't have to enumerate before as LOC provides us with an index for each item in the JSON
next_page = response_json['pages']['next'] # this line differs from LOC JSON API guide
if next_page is not None:
url = 'https:' + next_page # the JSON does not supply the https: for us so we need to add it
payload = {'fo': 'json'} # and we still need to supply format to get the JSON
response_json=get_loc_json(url, payload)
else:
break
Output
1 2 3 4 5 6 7 ... ... 2455 2456 2457 2458
2458!
Yep, we actually have 2,458 titles, 1 for each hit, though I cut a few so you didn’t have to scroll through them all. In addition to the next page, response_json['pages'] can tell us how many results we have per page, our current page, and what the total number of pages are. Here’s the code to see what fields are exposed to us at point pages.
print("Fields in response_json['pages']\n")
for field in response_json['pages']:
print(field)
Output
Fields in response_json['pages'] perpage last results first next current page_list total previous
Lists & Key Pairs
We have a list of keys that are paired with 1 or more values, though one of those possible values is None. So what is contained in each of the response_json['pages']['fields']?
Let’s run this one with a new query in case you’ve already surmised the total for Stryker’s Negatives. And I want to double-check that the code is working for more than just one query..
# input new entry
query = 'Texas'
# fill the payload with the new search term[s] and get a response in JSON
response_json = query_loc_json(query)
print("Your search '{}' returned {} hits.".format(query, get_loc_hits(response_json))
# What is the current page?
current_page = response_json['pages']['current']
print('\ncurrent page: {}'.format(current_page))
# What about total, per page, results, and next?
fields = ['total', 'per_page', 'results', 'next']
for field in fields: # if we have a field in fields
if response_json['pages'][field]: # and it exists here
print('\n{}: {}'.format(field, response_json['pages'][field])
Output
Your search 'Texas' returned 31550 hits. current: 1 total: 1578 perpage: 20 results: 1 - 20 next: //www.loc.gov/pictures/search/?q=Texas&sp=2
1578 total pages
If we do the math with 20 per page that’s a possible 31,560 items. We have 31,550 hits, so there must only be 10 hits on the last page. We can find the number of items on the last page quickly using len() and last.
last_page = response_json['pages']['last'] last_page_url = 'https:' + last_page + '&fo=json' last_page_json = requests.get(last_page_url).json() len(last_page_json['results'])
Output
10
Let’s Jump Forward
And we’re now able to output our more metadata in a more controlled fashion. For instance, getting the name of the photographer, the date, and the location associated with the first 25 images from the negatives Roy Stryker had hole punched.
Output
image 1 photographer: Rothstein, Arthur, 1915-1985 date: [1939 Jan.] location: Illinois--Herrin image 2 photographer: Wolcott, Marion Post, 1910-1990 date: [1938 Sept.] location: West Virginia--Jere image 3 photographer: Mydans, Carl date: [1936 June] location: Arkansas--Batesville image 4 photographer: Mydans, Carl date: [1936 June] location: Arkansas--Batesville image 5 photographer: Mydans, Carl date: [1936 June] location: Arkansas--Batesville image 6 photographer: Jung, Theodor, 1906-1996 date: [1935 Oct.] location: Indiana--Brown County image 7 photographer: Jung, Theodor, 1906-1996 date: [1935 Oct.] location: Indiana--Brown County image 8 photographer: Jung, Theodor, 1906-1996 date: [1935 Oct.] location: Indiana--Brown County ... ... image 23 photographer: Rothstein, Arthur, 1915-1985 date: [1935 Oct.] location: Virginia--Shenandoah National Park image 24 photographer: Rothstein, Arthur, 1915-1985 date: [1935 Oct.] location: Virginia--Shenandoah National Park image 25 photographer: Rothstein, Arthur, 1915-1985 date: [1935 Oct.] location: Virginia--Shenandoah National Park
Skipped entries for brevity’s sake
This is great info, but to get a clearer picture to start with, let’s remove some of it to get a better sense of our data.
#import libraries
from __future__ import print_function # this is Python 2.7 code
import requests
from time import sleep
import os
# set our search url and payload as shown in requests's quick guide:
# http://docs.python-requests.org/en/master/user/quickstart/
url = 'https://loc.gov/pictures/search/' # try to always use https
# payload info from:
# https://www.loc.gov/pictures/api#Search_15626900281916867_13804_7288827267039479
payload = {'q': 'Negative has a hole punch made by FSA staff to \
indicate that the negative should not be printed.',
'fo': 'json'}
response_json = requests.get(url, params=payload).json()
page_count = 0
while page_count < 2 and True: # only get a next if there is one!
for item in response_json['results']:
# let's limit to a max index of 25
item_index = item['index']
if item_index < 26:
print('image {}'.format(item['index']))
# answer more questions with metadata from the item page
item_url = 'https:' + item['links']['item'] + '?&fo=json'
item_json = requests.get(item_url).json()
for field in item_json['item']['place']:
location = field['title']
# photographers name is found under item > creators > title
for field in item_json['item']['creators']:
name = field['title']
# and date right under date
date = '{}'.format(item_json['item']['date'])
# first print of data
#print('photographer: {}\n'.format(name) + \
# 'date: {}\n'.format(date) + \
# 'location: {}\n.format(location))
# can we simplify this more?
# image 12
# photographer: Jung, Theodor, 1906-1996
# date: [1935 Oct.]
# location: Indiana--Brown County
# for name we can split on commas
# NOTE: some entries do NOT have dates!
try:
last, first, life = [x.strip() for x in name.split(',')]
name = first + ' ' + last
except ValueError:
last, first = [x.strip() for x in name.split(',')]
name = first + ' ' + last
# keep it simple and just find the digits
# then cat them together to get the date
digits = [x for x in date if x.isdigit()]
date = ''.join(digits)
# state before county or park
state, county = [x.strip() for x in location.split('--')]
location = state
# 2nd time printing
print('photographer: {}\n.format(name) + \
'date: {}\n'.format(date) + \
'location: {}\n'.format(location))
next_page = response_json['pages']['next']
if next_page is not None:
url = 'https:' + next_page # JSON does not supply https:
payload = {'fo': 'son'} # and need to request JSON
response_json = requests.get(url, params=payload).json()
page_count += 1 # increment page counter
sleep(2) # sleep for 2 seconds between pages
else:
break
Output
image 1 photographer: Arthur Rothstein date: 1939 location: Illinois image 2 photographer: Marion Post Wolcott date: 1938 location: Illinois image 3 photographer: Carl Mydans date: 1936 location: Illinois image 4 photographer: Carl Mydans date: 1936 location: Illinois image 5 photographer: Carl Mydans date: 1936 location: Illinois image 6 photographer: Theodor Jung date: 1935 location: Illinois image 7 photographer: Theodor Jung date: 1935 location: Illinois ... ... image 24 photographer: Arthur Rothstein date: 1935 location: Illinois image 25 photographer: Arthur Rothstein date: 1935 location: Illinois
Pretty powerful stuff
This is a good point at which to end this blog post. This has been a quick introduction to accessing the Library of Congress’s website with Python through their new JSON API. Below is a graph and some fiddly bits I learned about copying to and pasting from my clipboard in Terminal on macOs. I don’t know if comments have been turned on or off for this blog, but you can find me at jeremy.moore@txstate.edu
#import libraries
from __future__ import print_function # this is Python 2.7 code
import requests
from time import sleep
import pandas as pd
%matplotlib inline
from collections import Counter
location_counter = Counter()
# set our search url and payload as shown in requests's quick guide:
# http://docs.python-requests.org/en/master/user/quickstart/
url = 'https://loc.gov/pictures/search/' # try to always use https
# payload info from:
# https://www.loc.gov/pictures/api#Search_15626900281916867_13804_7288827267039479
payload = {'q': 'Negative has a hole punch made by FSA staff to \
indicate that the negative should not be printed.',
'fo': 'json'}
response_json = requests.get(url, params=payload).json()
page_count = 0
while page_count < 2 and True: # only get a next if there is one!
for item in response_json['results']:
# let's limit to a max index of 25
item_index = item['index']
if item_index < 26:
print('image {}'.format(item['index']))
# answer more questions with metadata from the item page
item_url = 'https:' + item['links']['item'] + '?&fo=json'
item_json = requests.get(item_url).json()
for field in item_json['item']['place']:
location = field['title']
# state before county or park
state, county = [x.strip() for x in location.split('--')]
location = state
location_counter[location] += 1
next_page = response_json['pages']['next']
if next_page is not None:
url = 'https:' + next_page # JSON does not supply https:
payload = {'fo': 'son'} # and need to request JSON
response_json = requests.get(url, params=payload).json()
page_count += 1 # increment page counter
sleep(2) # sleep for 2 seconds between pages
else:
break
location = pd.Series(location_counter)
location.sort_values(ascending=True).plot(kind='bath', figsize=(8,8))
for value in location.sort_values(ascending=False):
print(value)
Output
12 4 3 3 2 1
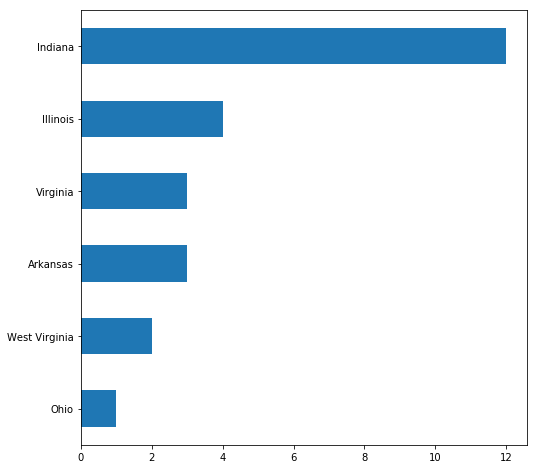
Graph of locations in first 25 results returned by our query
- NOTE: How I quickly calculated the first 1/10 of my output using the Terminal on my MacBook:
pbpaste and pbcopy will paste from and copy to your Mac’s clipboard, so I selected all of the text from our output and entered the command below in Terminal. The ‘|‘ pipe character (it’s found with the \ key under delete on my MacBook keyboard) takes output from one program and sends it to another. If you think about Mario and Luigi, but instead of a plumber moving between levels, it’s your data moving between programs.
$ some stuff is what I have entered on the command line (everything after ‘$ ‘) and the line below it is my output.
$ pbpaste | wc -c
32052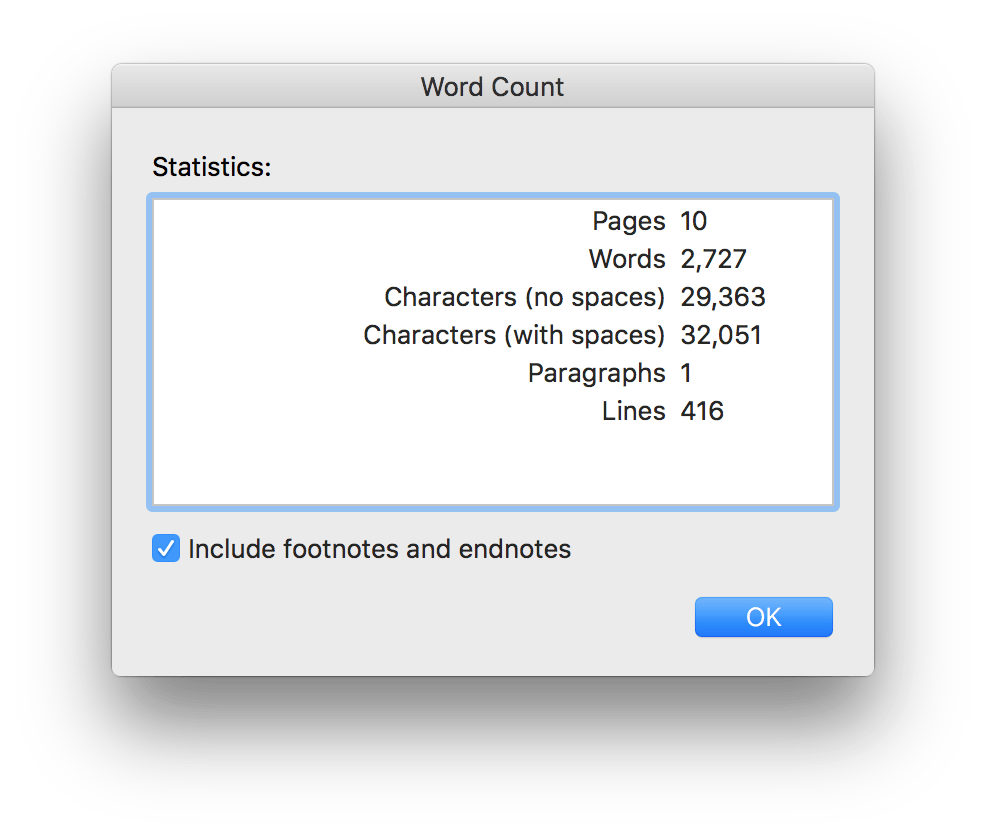
Microsoft Word character count
The above code took all of the text in my clipboard and sent it to program wc with option -c and returned 32052. wc is is a word counter and I chose to use option -c that counts the number of bytes in the input. With the alphabet I am using 1 byte = 1 character. I pasted it into Microsoft Word and took a screenshot of our word count.
I knew I only wanted to the first 1/10 of the output as it was just too much text to include in a blog so I loaded everything into a variable. We can load a variable by typing our previous command inside of $() and setting that equal to a container for the data, in this case signified by the letter x
$ x=$(pbpaste | wc -c)
If we echo x we just get back x.
$ echo x
x
We don’t want x, but the variable we set to x. We call it back by putting with a $ in front of the variable like $<variable> or $x.
$ echo $x
32052
Now we can do math on our variable. We can evaluate an arithmetic expression by enclosing it within 2 sets of parentheses preceded by a dollar sign. It takes longer to explain than to show: $((<math>))
$ echo $(($x/10))
3205
Note that our output is 3205 and not 3205.2 because we are doing integer math and integers are whole numbers. We can use a modulo operation to find the remainder by using the a percent sign % in our arithmetic expression, but that’s really getting far off-topic.
$ echo $(($x%10))
2
I used the program head that returns the beginning of a file and said I only wanted 3205 bytes with option -c and piped that back to my clipboard with pbcopy to paste into WordPress.
$ pbpaste | head -c 3205 | pbcopy
So now if I call pbpaste, it only contains what was last copied into it, the first 3205 bytes:
$ pbpaste | wc -c
3205