
This post builds on my last one: Searching the Library of Congress with Python and their new JSON API, which is why I’ve added Part 2 to the end of the title. Before we dive back into the Library of Congress‘s JSON API, some housekeeping items:
- Even though the Library of Congress’s website is loc.gov, the abbreviation for Library of Congress is LC
- I tried to find a press-ready image of NBC‘s old The More You Know logo I could add here, but
- the updated logo doesn’t make me hear the jingle in my head
- I did find Megan Garber‘s 2014 article covering the PSA series for The Atlantic that has some classic video I enjoyed
- I tried to find a press-ready image of NBC‘s old The More You Know logo I could add here, but
- As of October 2017, LC has expressly stated in a disclaimer that their JSON API is a work in progress. Use at your own risk!! We might (will likely) change this!
Recap on Stryker’s Negatives Project
I recently came across Michael Bennett‘s article Countering Stryker’s Punch: Algorithmically Filling the Black Hole in the latest edition of code4lib: <– GREAT STUFF!
He’s using Adobe Photoshop and GIMP to digitally restore blank areas in images due to a hole punch having been taken to the physical negative.
Current Task
Use the Library of Congress’s JSON API to download all of the hole punch images and their associated metadata.
Future Goals
Future possibilities include computer vision and machine learning applications to algorithmically fill the black holes, but let’s start by first defining and retrieving the initial data set.
Main Resource
Our main resource is the LC API Page.
Getting Started
I found the LC’s how-to example page in their LC Github account really helpful when getting started and have modeled my research following their suggestions when and where their code worked for me.
To the API!
https://www.loc.gov/pictures/api#Search_15626900281916867_13804_7288827267039479
``` http://loc.gov/pictures/search/?q=<query>&fo=json Searches descriptive information for the search terms specified by <query>. Options Search Options q - query, search terms (None) fa - facets, format = <field>|<facet value> (None) co - collection (None) co! - _not_ collection (None) op - operator (AND) va - variants, (True) fi - fields (None/"text") Results Options c - count (20) st - style, (list) sp - start page, (1) si - start index (1) fo - format ```
# import libraries
from __future__ import print_function # I'm using Python 2.7
import requests
import json
import os
import random
import pandas as pd
from collections import Counter
from time import sleep
%matplotlib inline
# higher dpi graphs for Retina Macbook screen
%config InlineBackend.figure_format = 'retina'Search the LC
url = 'https://www.loc.gov/pictures/search'
query = 'Negative has a hole punch made by FSA staff to indicate that the negative should not be printed.'
payload = {'q': query,
'fo': 'json'
}
response_json = requests.get(url, payload).json()
lc_total_hits = response_json['search']['hits']
print("Your search '{}' returned {} hits.".format(query, lc_total_hits))
Output
Your search 'Negative has a hole punch made by FSA staff to indicate that the negative should not be printed.' returned 2458 hits.Count = total hits?
According to the API, by default LC returns a count, c, of 20 results per page, but since we know we want ALL of the results returned by query can we get all of them at once?
If you haven’t caught on to to my rhetorical strategy using rhetorical questions yet, the answer is yes, but we need to update payload; to include this new option.
# Add counts 'c' to our payload and set it equal to hits
payload['c'] = lc_total_hits
response_json = requests.get(url, payload).json()
# did we succeed getting all of the results in one page?
print('Total results: {} | Results per page: {} '.format(lc_total_hits, response_json['pages']['perpage']))
Output
Total results: 2458 | Results per page: 2458
It worked!
We can now save a single JSON file with all of our search results and start asking our data some questions.
# set filename and path for data
path = './files/json/'
# if our directory path doesn't exist, MAKE it exist
if not os.path.exists(path):
os.makedirs(path)
filename = 'all_results_json.txt'
path_file = path + filename
# if we have a path & filename
if path_file:
# write/dump JSON to disk
with open(path_file, 'w') as f:
json.dump(response_json, f)
if os.path.isfile(path_file):
print('Something exists as a file at {}'.format(path_file))
Output
Something exists as a file at ./files/json/all_results_json.txt
Something was written to disk
So let’s see if we can read it back out. When we do the total items in results should equal 2,458.
# read/load JSON file into memory
with open(path_file, 'r') as f:
response_json = json.load(f)
results = response_json['results']
print('Number of results: {}'.format(len(results)))
Output
Number of results: 2458
Take care with counting
Remember that computers start the index with 0, while the LC index written into the JSON starts with 1. Be sure you’re aware of where counts start and stop when you’re accessing items by a number!
def test_range(i):
for iteration in xrange(i):
print('iteration: {} in range i: {}'.format(iteration, i))
test_range(10)
Output
iteration: 0 in range i: 10
iteration: 1 in range i: 10
iteration: 2 in range i: 10
iteration: 3 in range i: 10
iteration: 4 in range i: 10
iteration: 5 in range i: 10
iteration: 6 in range i: 10
iteration: 7 in range i: 10
iteration: 8 in range i: 10
iteration: 9 in range i: 10Zero-indexed iteration
So iteration for xrange(i) is a loop that starts at 0 and adds 1 on each iteration, but stops before iteration==i
Let’s see what index number we get using our xrange loop through the JSON data.
for iteration in xrange(10):
print('iteration: {} | LC index: {}'.format(iteration, results[iteration]['index']))Output
iteration: 0 | LC index: 1
iteration: 1 | LC index: 2
iteration: 2 | LC index: 3
iteration: 3 | LC index: 4
iteration: 4 | LC index: 5
iteration: 5 | LC index: 6
iteration: 6 | LC index: 7
iteration: 7 | LC index: 8
iteration: 8 | LC index: 9
iteration: 9 | LC index: 10Now we’re getting somewhere!
Let’s get a random number from the LC index and print the title for that image. While we are at it, though, let’s make sure our random number can be any of our 2,458 images.
total_results = len(results)
population = xrange(total_results)
# random.sample(population, sample number)
random_list = random.sample(population, total_results)
# sort random_list and access first and last numbers
sorted_list = sorted(random_list)
first_number = sorted_list[0]
last_number = sorted_list[-1]
def item_index_title(results, i):
return results[i]['index'], results[i]['title']
first_index, first_title = item_index_title(results, first_number)
last_index, last_title = item_index_title(results, last_number)
# double-check we're pulling from all 2,458 possibilities
print('random_list -- Total numbers: {}'.format(len(random_list)))
print('\nFirst number: {} | First index: {}'.format(first_number, first_index),
'\n{}\n'.format(first_title),
'\nLast number: {} | Last index: {}'.format(last_number, last_index),
'\nLast title: {}'.format(last_title))Output
random_list -- Total numbers: 2458
First number: 0 | First index: 1
[Untitled photo, possibly related to: U.M.W.A. (United Mine Workers of America) official, Herrin, Illinois. General caption: Williamson County, Illinois once produced 11,000,000 tons of coal a year, and led the state in output. Since 1923 output has steadily declined until now it falls short of 2,000,000 tons. At one time, sixteen mine whistles blowing to work could be heard from the center of Herrin. Now only two mines are working and these two will probably be abandoned within the next year. The Herrin office of the U.M.W.A. was once the most active in the state. Today it is no longer self sustaining. These pictures were taken in the Herrin U.M.W.A office on a day when the mines were not working]
Last number: 2457 | Last index: 2458
Last title: [Untitled photo, possibly related to: Floyd Burroughs, Jr., and Othel Lee Burroughs, called Squeakie. Son of an Alabama cotton sharecropper]Let’s grab 100 random numbers!
# random.sample(population, sample number)
random_list = random.sample(population, 100)
# print our random list of numbers
print(random_list)Output
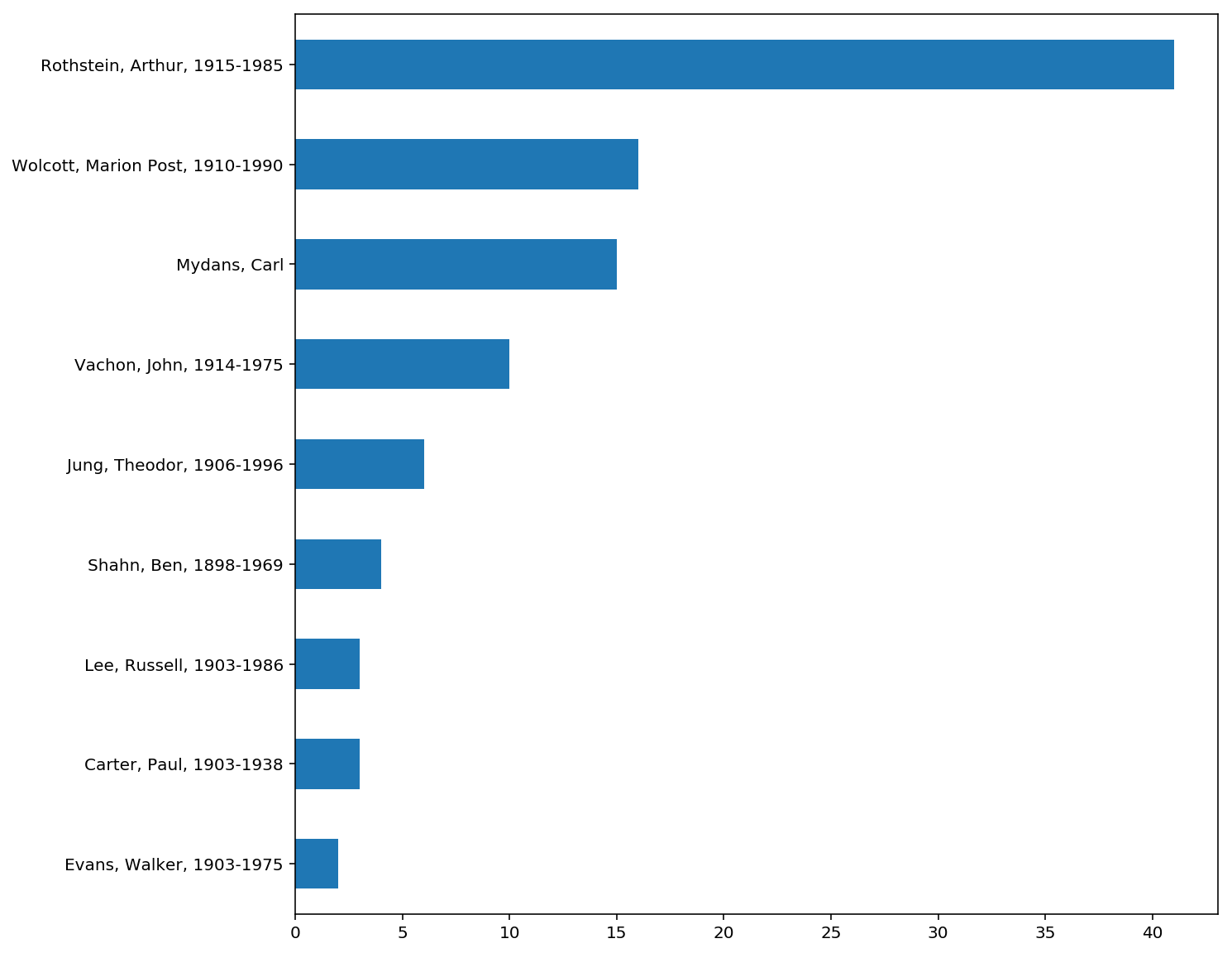
[1294, 2124, 721, 1502, 809, 1302, 1505, 1530, 799, 78, 1420, 1954, 1459, 24, 370, 1664, 1988, 641, 1845, 6, 1033, 2383, 521, 1266, 1433, 659, 1389, 2118, 921, 1245, 2184, 1462, 726, 1856, 458, 1515, 2013, 200, 1477, 2368, 2275, 1094, 490, 1096, 1496, 1832, 146, 787, 571, 60, 1933, 454, 2412, 688, 191, 2431, 1308, 261, 1241, 2155, 1153, 793, 1104, 1348, 1169, 88, 982, 535, 2352, 574, 1384, 1412, 1931, 1722, 712, 270, 55, 182, 1427, 816, 2381, 1014, 1355, 1529, 2022, 140, 92, 1670, 1525, 1506, 1220, 2425, 95, 1026, 1776, 2227, 2165, 788, 1392, 272]Grab 100 names!
1 name for each of the 100 random index number AND uniquely sort them alphabetically
names = []
for i in random_list:
# define what we're looking for
name = results[i]['creator']
names.append(name)
# use a set to make our list of names unique and sort in place
sorted_names = sorted(set(names))
for name in sorted_names:
print(name)Output
Carter, Paul, 1903-1938
Evans, Walker, 1903-1975
Jung, Theodor, 1906-1996
Lee, Russell, 1903-1986
Mydans, Carl
Rothstein, Arthur, 1915-1985
Shahn, Ben, 1898-1969
Vachon, John, 1914-1975
Wolcott, Marion Post, 1910-1990Count how many of each name?
# instantiate a name counter
name_counter = Counter()
for i in random_list:
# define what we're looking for
name = results[i]['creator']
# add it to our counter
name_counter[name] += 1
# serialize our counter
names = pd.Series(name_counter)
# print our serialized count
print(names)Output
Carter, Paul, 1903-1938 3
Evans, Walker, 1903-1975 2
Jung, Theodor, 1906-1996 6
Lee, Russell, 1903-1986 3
Mydans, Carl 15
Rothstein, Arthur, 1915-1985 41
Shahn, Ben, 1898-1969 4
Vachon, John, 1914-1975 10
Wolcott, Marion Post, 1910-1990 16
dtype: int64Graph our random 100 names
# graph our names by count names.sort_values(ascending=True).plot(kind='barh', figsize=(10,10))
Output
GRAPH ALL OF THE RESULTS
# instantiate a new name counter
name_counter = Counter()
# loop through all of our results
for i in xrange(len(results)):
# define what we want
name = results[i]['creator']
name_counter[name] += 1
names = pd.Series(name_counter)
# graph our names by count
names.sort_values(ascending=True).plot(kind='barh', figsize=(10, 10))Output
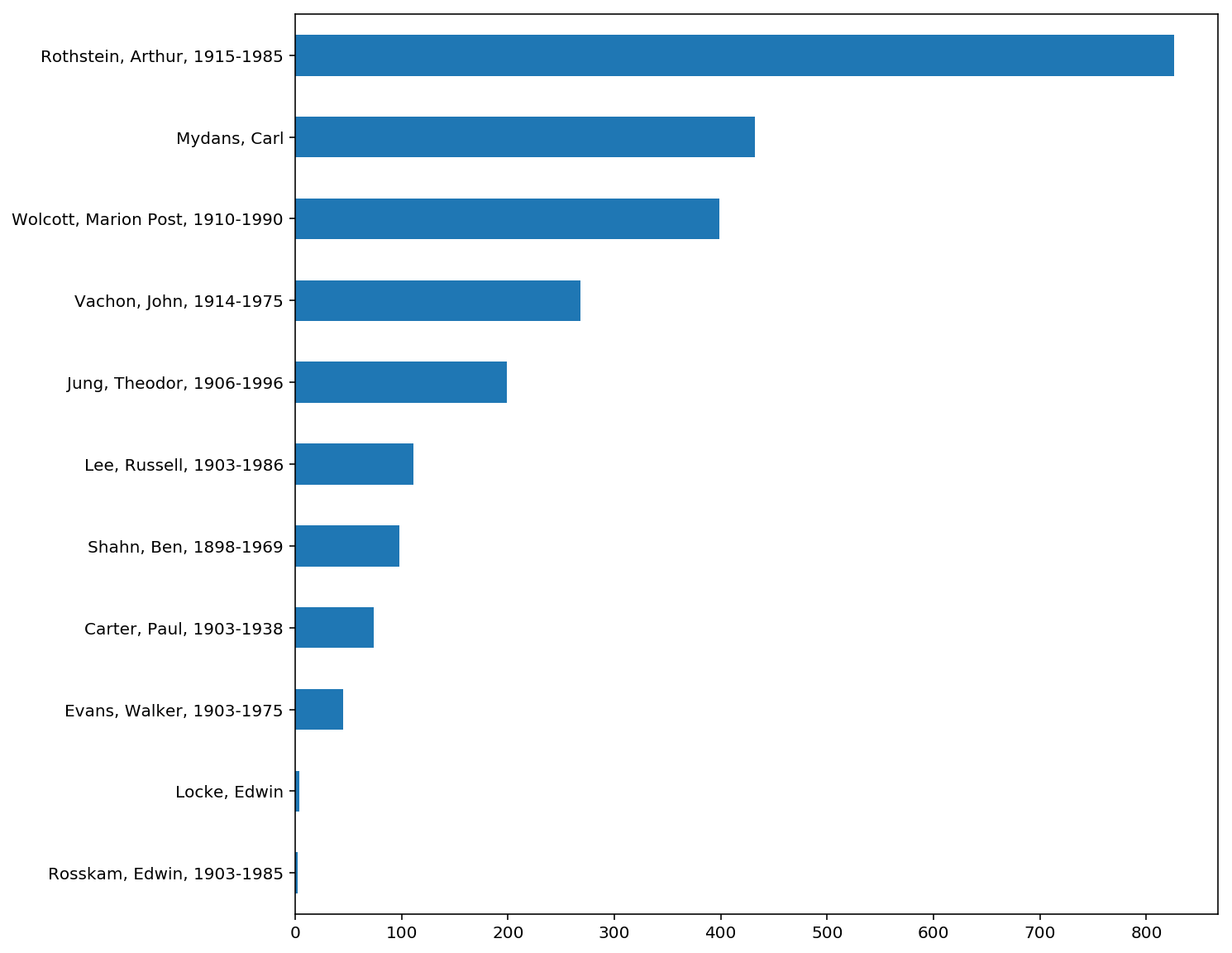
Look at that distribution
Rothstein has almost double the number of hole punched negatives of the following photographer, Carl Mydans.
How about a list of locations? Well, this info was not saved in all_results_json.txt, so we have to get it from the JSON from each individual item’s page. Since we are accessing 2,458 pages, it makes sense to save them to disk for later.
# loop through all results
for i in xrange(len(results)):
# set filename and path for data
path = './files/json/'
# zero pad out to 4 digits
filename = 'image_{:04d}_json.txt'.format(i+1) # add 1 to i for LC index number
path_file = path + filename # in future projects use os.join
# if there is already a file and it's size is over 0 bytes
if os.path.isfile(path_file) and os.stat(path_file).st_size > 0:
pass
else:
# get location info from individual item page
item_url = 'https:' + results[i]['links']['item'] + '?&fo=json'
item_json = requests.get(item_url).json()
# write JSON file for each item to disk to reuse data later
# if our directory path does not exist, MAKE it exist!
if not os.path.exists(out_path):
os.makedirs(out_path)
# if we have a path & filename
if path_file:
# write JSON to disk
with open(path_file, 'w') as write_file:
json_dump(item_json, write_file)
if os.path.isfile(path_file):
print('Downloaded something to {}'.format(path_file))Output
Downloaded something to ./files/json/image_0001_json.txt Downloaded something to ./files/json/image_0002_json.txt ... I'm skipping a bunch here Downloaded something to ./files/json/image_2458_json.txt
*_json.txt vs *.JSON & Count the locations
In future projects I will just explicitly call the file <filename>.json, but in this project I stuck to old habits of writing everything to temporary <filename>.txt files instead.
While counting the locations, go ahead and limit the output to just the level of US state (plus Canada).
# instantiate new location counter
location_counter = Counter()
# loop through all results
for i in xrange(len(results)):
# set path and filename
path = './files/json/'
# zero pad out to 4 digits
filename = 'image_{:04d}_json.txt'.format(i+1) # add 1 to i for LC index number
path_file = path + filename
# if path and filename exists
if os.path.isfile(path_file):
# load our item-level JSON
with open(path_file, 'r') as read_file:
item_json = json.load(read_file)
# define what we want
location = item_json['item']['place'][0]['title']
# get just the state before the double hyphen
location = location.split('--')[0]
# split again on "space + open parentheses" because of "New York (State)"
location = location.split(' (')[0]
# add it to the counter
location_counter[location] += 1
locations = pd.Series(location_counter)
print(locations)Output
Alabama 77 Arkansas 49 Canada 1 District of Columbia 78 Florida 117 Georgia 76 Illinois 40 Indiana 128 Iowa 4 Kansas 18 Kentucky 12 Louisiana 36 Maine 8 Maryland 258 Massachusetts 72 Michigan 9 Minnesota 54 Mississippi 28 Missouri 26 Montana 13 Nebraska 61 New Hampshire 12 New Jersey 81 New York 75 North Carolina 84 North Dakota 21 Ohio 239 Pennsylvania 96 Tennessee 33 Texas 3 Vermont 143 Virginia 75 West Virginia 414 Wisconsin 17 dtype: int64
Make a download list
Make a list of all of the ‘largest’ size TIFF for each result that we can use to download from overnight.
# loop through all results
for i in xrange(len(results)):
# set path and filename
path = './files/json/'
# zero pad out to 4 digits
filename = 'image_{:04d}_json.txt'.format(i+1) # add 1 to i for LC index number
path_file = path + filename
# if path and filename exists
if os.path.isfile(path_file):
# load our item-level JSON
with open(path_file, 'r') as read_file:
item_json = json.load(read_file)
# define what we want
largest_image_url = 'https:' + item_json['resources'][0]['largest']
original_filename = largest_image_url.rsplit('/', 1)[1]
tif_filename = '{:04d}_'.format(i+1) + original_filename
path = './files/images/largest/'
# if our directory path doesn't exist, MAKE it exist!
if not os.path.exists(path):
os.makedirs(path)
path_image = path + tif_filename
image_urls = './files/images/images_urls.txt'
# open a file to write to in mode append
with open(image_urls, 'a') as write_file:
write_string = path_image + ' ' + largest_image_url + '\n'
write_file.write(write_string)Now download!
# now download!
with open(image_urls, 'r') as read_file:
for line in read_file:
path_image, largest_image_url = line.split()
tif_filename = path_image.rsplit('/', 1)[1]
if os.path.isfile(path_image) and os.path.getsize(path_image) > 10000:
print('{} already downloaded at {}'.format(tif_filename, path_image))
else:
print('download: {}'.format(path_image))
# use wget to download images
os.system("wget -c --show-progress -O {} {}".format(path_image, largest_image_url))
if os.path.isfile(path_image) and os.path.getsize(path_image) > 10000:
print('{} downloaded at {}'.format(tif_filename, path_image))
sleep(10) # sleep 10 seconds if we downloaded a filecaffeinate
I am writing and running this code on an Apple laptop that likes to go to sleep and stop downloading files in the background. I get around this using the command-line program caffeinate. I’m on OS X El Capitan version 10.11.6 and it came installed on my machine
To keep the system active and downloading overnight, I used caffeinate with a Python script that’s pretty much a cut and paste of the code above after # now download!. I only needed to add import os, from time import sleep, and image_urls = './files/images/image_urls.txt before the # now download! comment and saved it to download.py.
import os from time import sleep image_urls = './files/images/image_urls.txt # now download!
I started the download script with caffeinate -i python download.py and headed home for dinner. Upon my return the next morning all images had been downloaded.
Now we’re ready for image processing!
Thanks!
You can find me in Alkek Library at Texas State University and reach me at jeremy.moore@txstate.edu
If this blog was of any use to you, please send me and email and let me know!
Note: Use sed to search and replace
At the end of my last blog post I wrote about using pbpaste and pbcopy to paste from and copy to my clipboard from the command-line. I needed to change the code for graphing names to locations and, while there were other necessary changes like downloading item-level JSON and opening said file, some of the code is the same with just name changed to location.
This substitution is something I can quickly and easily do using pbpaste & pbcopy with sed.
Sed, among other things, allows me to specify a pattern to look for in the input and what I would like to substitute for it in the output. One thing I really like about Jupyter Notebooks is the ease we can call up the command line — just prepend your code with a !.
Changing name to location is as simple as !pbpaste | sed '/s/name/lcoation/g' | pbcopy
That syntax breaks down to '<substitute>/<pattern1>/<pattern2>/<globally>' so don't stop with the first substitution found, but replace EVERY instance of pattern1 with pattern2 then we pipe it back to the clipboard to paste into our code.