
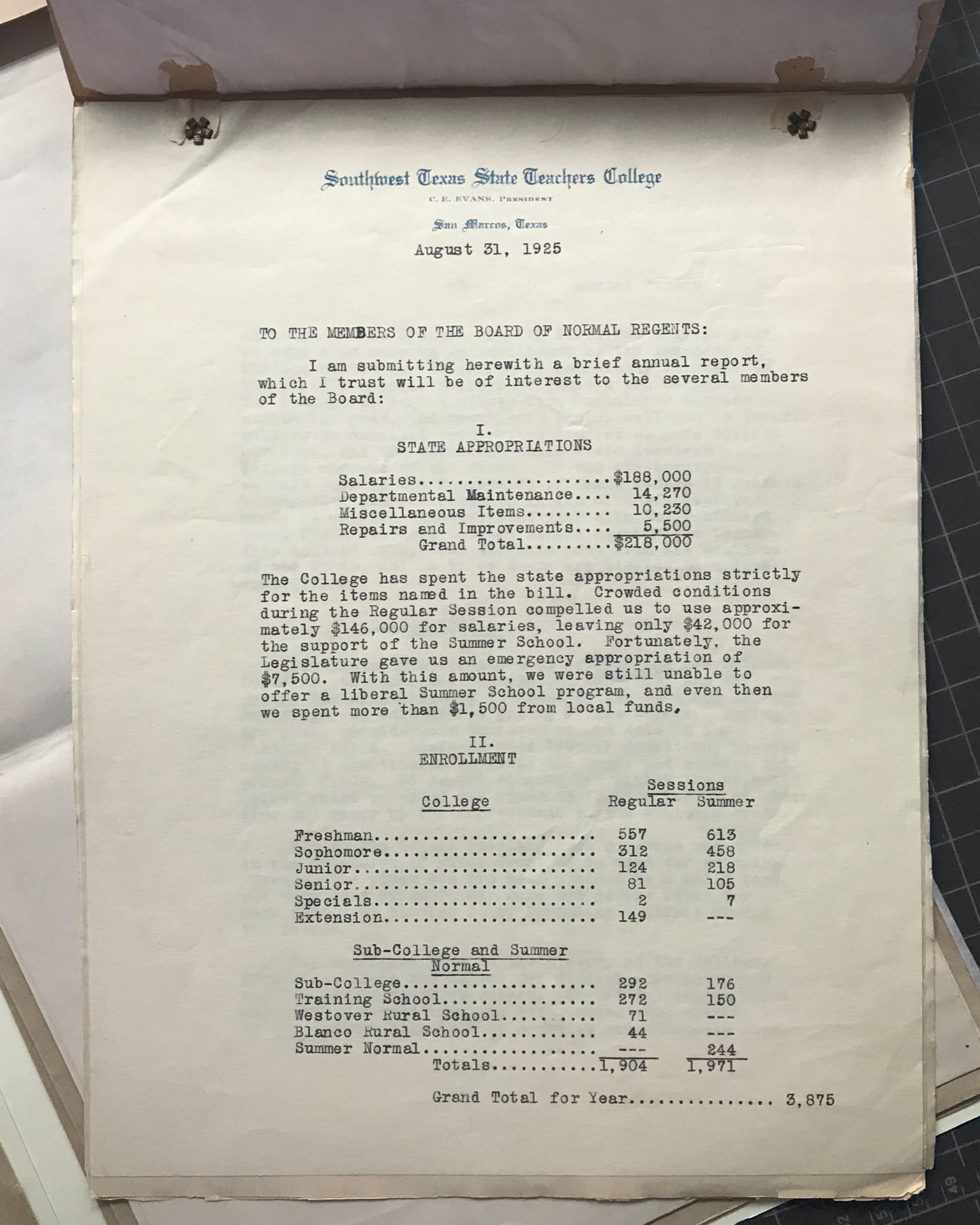
Texas State University is a member of the Texas State University System, currently governed by a nine-member Board of Regents who are appointed by the governor and confirmed by the Senate. For their quarterly meetings, the President of Texas State prepares a report of University activities and proposals for the Board’s review. While the reports that are now released are digitally accessible, the University Archives at Texas State holds the official paper records of these reports, the earliest of which dates back to 1923. Since these records include an overview of budgets, enrollment, faculty salaries, and construction and renovation details, in addition to a broad look at notable events occurring at the University, they’re of great value to local researchers and administration and a high priority for digitization to increase the ease of access to these materials. Due to age and variability of the physical reports, the oldest bound material, ranging from 1923 – 1969, was captured separately in the workflow described below.
Project Specs:

Start Date: September 17, 2019
Completion Date: December 16, 2019
Total Images Captured: 7,031
Total PDFs Created: 183
Capture Method: Fujitsu fi-6670 multi feed scanner; Sony A7R II
Programs Used: Paper Stream Capture, Capture One, ScanTailor Advanced. Photoshop, Adobe Acrobat, Jupyter Notebook

Two stacks of bound copies prior to digitization.
The 32 bound volumes contained 186 individual reports, plus one box of older material that contained potential duplicates. Prior to scanning, pages from the box of potential duplicates were matched to records in the bound volumes.

Dis-binding in progress
Each bound volume was disassembled using a scalpel to remove the cover boards, end sheets, and spine material. Once all excess binding material was removed, each page was carefully peeled from its text block by hand and the edges were cleaned of debris. Due to the page perforations, this allowed us to maintain maximum integrity of the original document and enabled most material to be scanned on a Fujitsu sheet feed scanner. After the pages were separated, each individual report was flagged to make identification easier during the scanning process.
Some of the oldest reports were made of onion skin pages

Detail of damaged page and brass binding
A customized Excel spreadsheet was used to track all project details during processing and included a count of the number of pages, who scanned it and when, and any notes that accompanied the volume. Any pages that needed special consideration, such as non-standard sizes, delicate material such as onion skin paper, and separately bound material were flagged and marked in the notes for separate handling.
Excerpt of tracking document showing notations of errors in final quality control
The Fujitsu fi-6670 multi feed duplex scanner was used to capture one volume at a time and utilizes Paper Stream Capture for basic processing. Even for more standardized materials from later years, care was needed to make sure the pages were not damaged. Around 20 pages were typically scanned at once in small batches to preserve integrity and also ensure an accurate count of all pages, both physical and digital. Any pages that were onion skin or of non-standard size were marked so those pages could be captured all at once, which made the workflow both more efficient and easier to use for digital technicians just learning the process.
Once each report was scanned and the individual files were exported into a folder labeled with the specific date of the report, the tracking sheet was updated the number of digital files created. After each volume was scanned, it was placed in folders chronologically in archival storage for the archivist. Each cover board was then recycled.

Scanned reports after being processed and placed into folders.
Once all sheet feed scanning was completed, a Sony A7R II with a FE 90 mm F2.8 Macro G OSS lens was to capture all pages that could not be safely scanned on the Fujitsu. Onion skin paper was backed with white foam core to yield the most legible results.

Sony capture station used to photograph onion skin and delicate or damaged pages.
ScanTailor Advanced was used to crop, set margins, and convert most images into bitonal TIFFs. Any images that did not convert well to the black and white text of a bitonal document were converted to grayscale for better text legibility. These grayscale images were then brought into Photoshop for final levels and tone adjustments to produce clearer results. Any corrections to bitonal files were then compressed using ImageMagick in the command line to Group 4 compression and added to their correct locations in the corresponding digital report..

Example of final document output. Legal Size. Bitonal. 600 dpi.
Before creating the PDF, we performed an initial quality check of each report confirming that text was not cut off, pages were not skewed or rotated incorrectly, that all text was legible, and made sure there were not any discrepancies in page count and sequence. We then used Python scripts in Jupyter Notebook to quickly batch check the consistency of image file format, color space, size, and compression, as well as fix any outliers. Once all TIFF files were checked, a PDF was created in Jupyter Notebooks as well and optimized in Adobe Acrobat. Optical Character Recognition (OCR) was also applied at this stage to ensure each document was keyword searchable.


Examples of final document output with notations. Letter Size. Grayscale. 400 dpi.